
最新のプロセスデータヒストリアンは、1秒以下の非常に高いサンプリングレートが可能です。これにより、非常に詳細な高頻度プロセス分析が容易になりますが、長期間にわたってデータを視覚化するとパフォーマンスが低下する可能性もあります。たとえば、1 年間 1 秒間隔で収集された 1 つのタグは、3,150 万を超える個別のデータ ポイントを生成します。最速のサーバーやネットワーク・インフラストラクチャーであっても、ビジュアライゼーション・クライアントにその量の情報を提供するには、かなりの時間が必要です。
dataPARC は、パフォーマンスデータエンジン (PARCpde) でこの問題を解決しました。PARCpdeは、スマートなアルゴリズムを利用して、トレンドに最適化されたデータを含むセカンダリアーカイブを維持し、クライアントに転送して「思考のスピード」で表示することができます。
PARCpdeには、指定された期間(シフト、日数など)または製品実行(グレード、ロット、バッチなど)の統計への高速アクセスを容易にするためのカスタム集計計算とアーカイブも含まれています。
PARCpdeのパフォーマンス
トレンド表示は、多くの場合、多数のタグが含まれ、場合によっては何年にもわたる運用期間に及ぶため、通常、最もリソースを大量に消費するタイプのデータ視覚化です。以下の表示例には、53 個のタグが含まれています。これらすべてのタグの平均サンプリングレートが5秒で、ユーザーが1年分の生データを表示したい場合、トレンドクライアントはサーバーから 3億3,400万 の個別データポイントを取得し、ディスプレイにレンダリングする必要があります。各データポイントの標準サイズが10バイトであると仮定すると、必要なデータ転送は 3.34ギガバイトになります。ネットワークインフラストラクチャによっては、非常に時間がかかるか、深刻なネットワーク輻輳を引き起こす可能性があります。
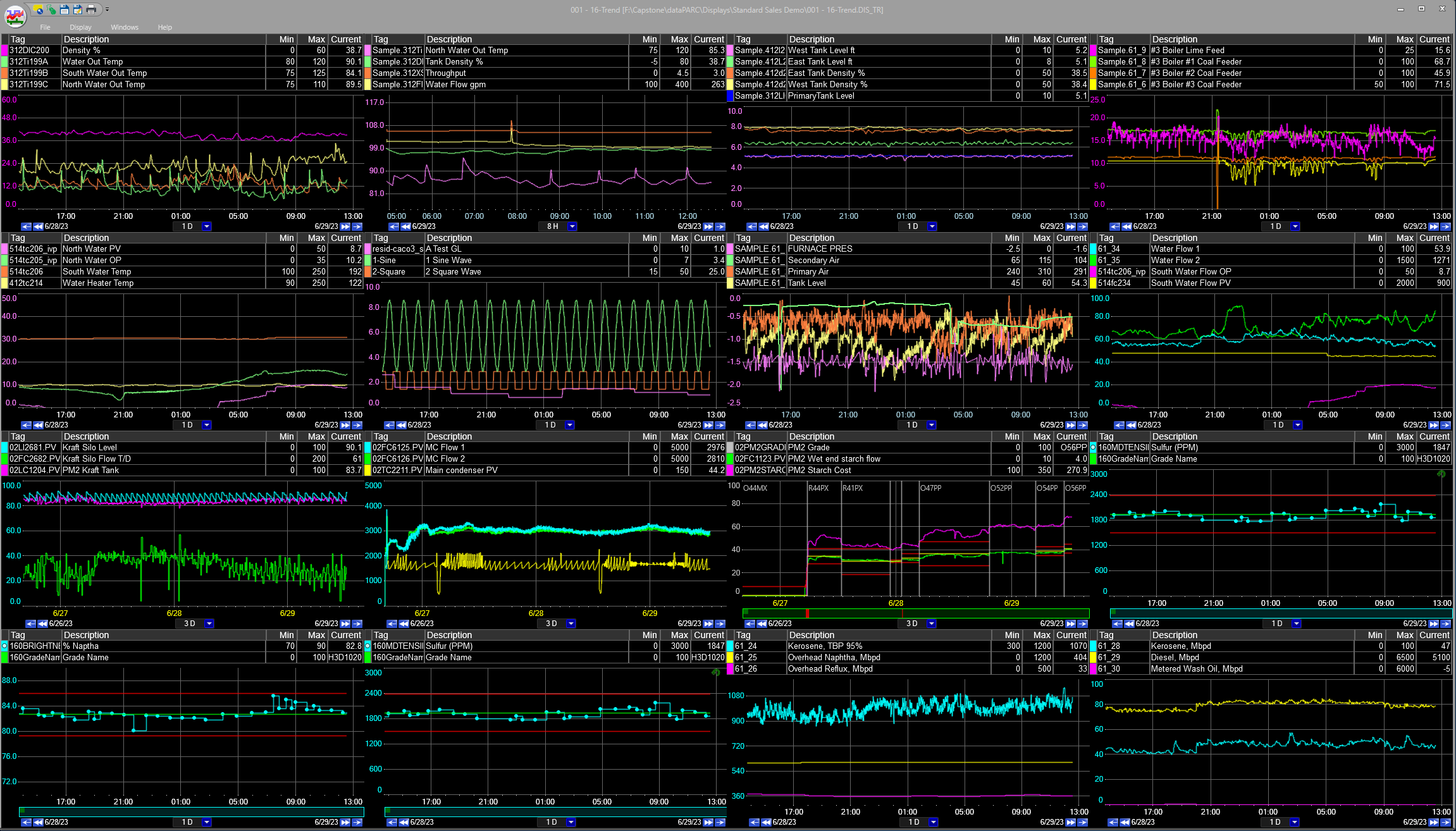
ただし、PARCpdeは、トレンドプロットの視覚的な影響に影響を与えることなく、データポイントの量を大幅に削減するトレンド最適化データをクライアントに提供します。これにより、特にトレンドの期間が長い場合、パフォーマンスが大幅に向上します。

カスタム集計の取得時間は、データポイントの数が少なく、事前に計算された統計がセカンダリアーカイブで使用できるため、通常はさらに高速です。これにより、傾向、中心線、および Excel アドイン データ抽出のパフォーマンスが向上します。
PARCpde アーキテクチャ
PARCpde は、dataPARC サーバー・アプリケーションのコンポーネントとして組み込まれています。アグリゲート・アーカイブ・サービス(PARCaggregate)は、一定の間隔(通常は1時間に1回)で実行され、トレンドに最適化された履歴データとカスタム・アグリゲートのセカンダリ・アーカイブを作成します。このセカンダリトレンド最適化アーカイブは、1日を超える期間のPARCviewトレンドデータリクエストを満たすため、または特定の時間タイプが選択されている場合に自動的に利用されます。ロールアップアーカイブサービス(PARCrollupサーバー)は継続的に実行され、要求に応じてPARCviewディスプレイに製品の実行、グレード、またはその他のイベントベースの集計を提供します。
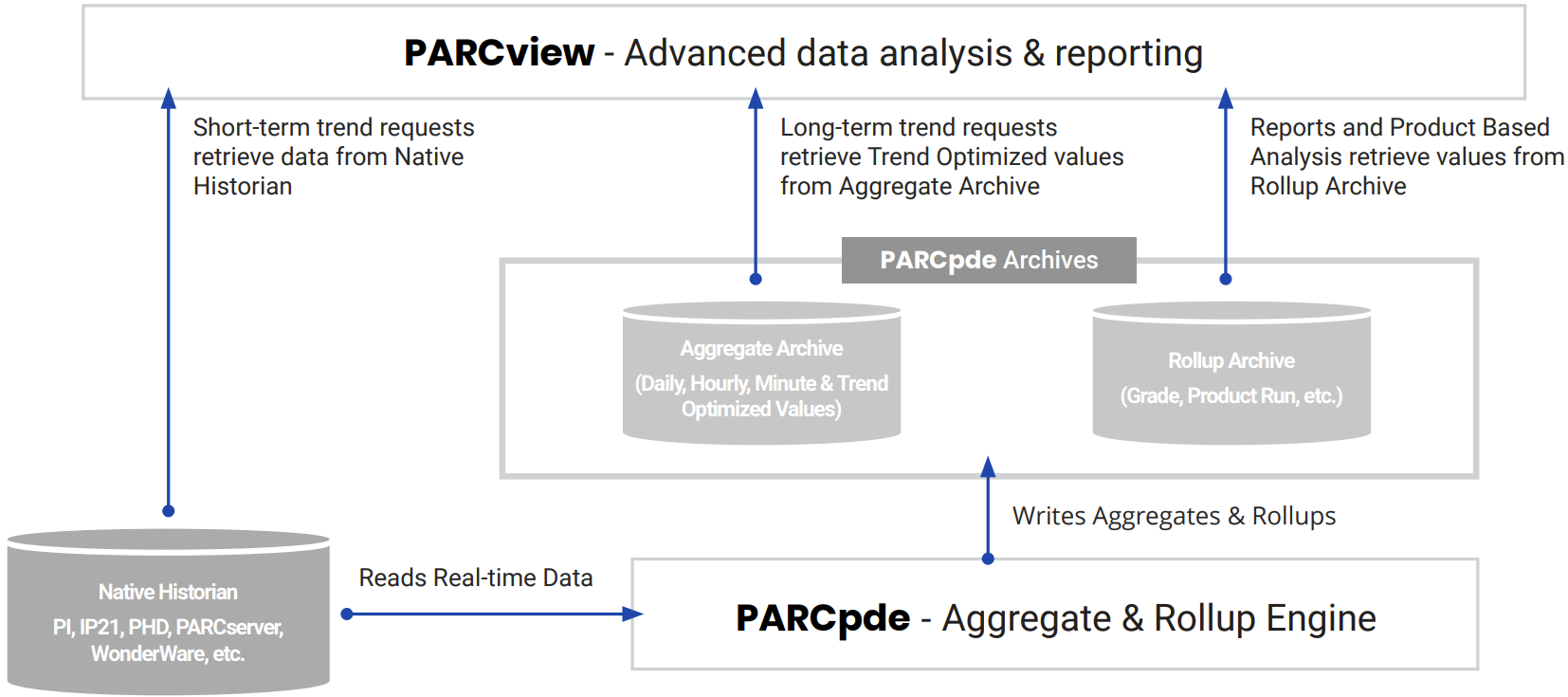
データ・ソース集計構成
[System Configuration -> Source]でアグリゲートに関して、いくつかのオプションを使用できます。ソースごとに、[OPC UA 構成] タブの下に、集計処理をカスタマイズできる 3 つのセクションがあります。
集約ソース
集計タイプごとに、計算には 2 つのオプションがあります。
ヒストリアン: 利用可能な場合、PARCview ツールは事前に計算された集計値をヒストリアン (通常は PARCaggregate) から読み取ります。
ProcessRaw: 集計は、生データに基づいて PARCview ツールによってアドホックに計算されます。
PARCAggregate ソース
これらのボックスをオンにすると、各期間の値を計算して保存するように PARCaggregate が構成されます。
プロットソース
これらのオプションは、トレンド表示で集計を使用してデータをプロットする方法を決定します。
プロットソース:
ヒストリアン: 選択すると、トレンドはソースヒストリアン(利用可能な場合)から事前に計算されたプロット削減データを利用します。これには、PARCaggregateによって計算されたプロット最適化データが含まれます。
生の処理: 選択すると、トレンドは生のヒストリアンデータからプロット削減データを「オンザフライ」で計算します。これにより、プロットの読み込み時間が長くなります。
UseAggregateSubstitute: 選択すると、以下のフィールドで指定されているように、Trendはプロット最適化データの代わりに代替集計を使用します。
集計代替: 上記で「UseAggregateSubstitute」が選択されている場合に、プロットする集計のタイプと期間を指定します。これには、選択したアグリゲートをPARCaggregateで設定する必要があります。
PARCaggregate greater than: トレンドのタイムスパンがこの日数より大きい場合は、PARCaggregateプロット削減を使用します。これは、上記で「ヒストリアン」プロットソースが選択されている場合にのみ適用されます。
PARCaggregate サービス
PARCaggregate サービスは、生の履歴データからプロット最適化データセットを計算します。また、日次、時間単位、分単位の集計データを生成することもできます。計算とアーカイブは、1 日 1 回、指定された時間に実行されます。
重要な注意事項
PARCaggregate は、dataPARC ヒストリアン、または .NET データ系列を使用するその他のデータソース (PI、PHD、SQL ソースなど) と連携します。
ただし、ctc_processtagsテーブルに存在するタグのみを処理するため、すべてのタグが含まれていることを確認するには、dataPARC Historian 以外のソースに対しても PARCtagSync を実行する必要があります。
慰める
メインの PARCaggregate コンソールビューには、集計計算用に設定されたソースのグリッドが表示されます。
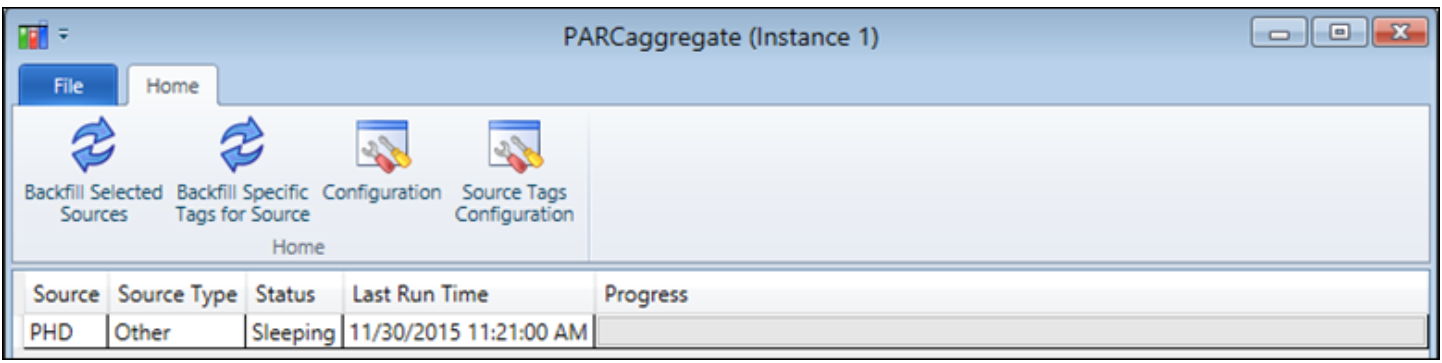
ソース設定
各 dataPARC ソースは、PARCaggregate 内で個別に構成できます
オプションのリストを以下に示します。PARCpde実装では「プロット削減の計算」を選択する必要があることに注意してください。
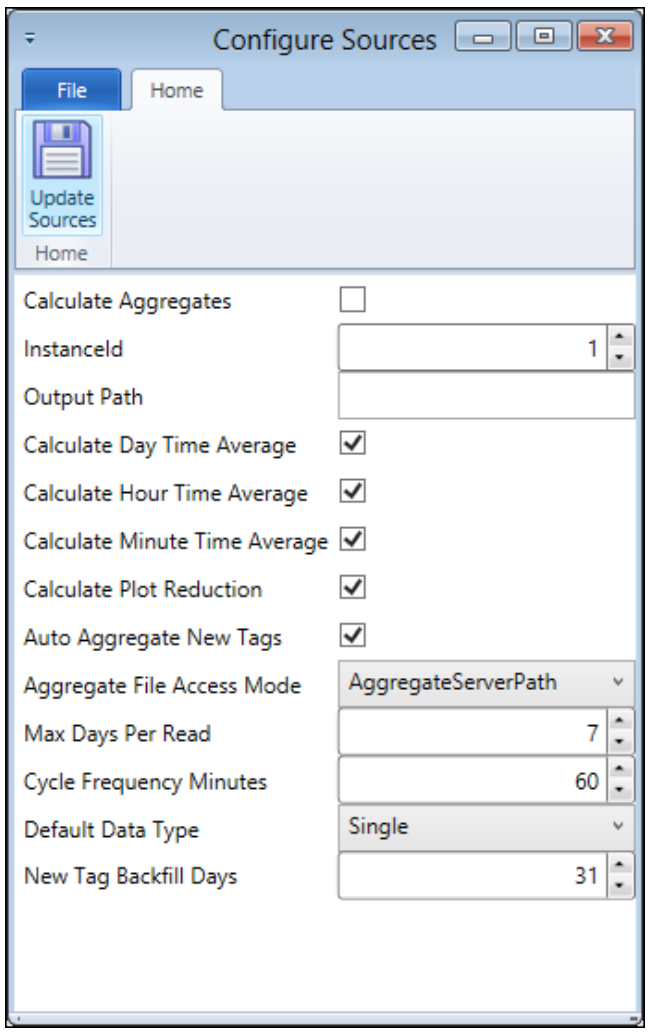
ソースタグの設定
各ソース内で、個々のタグごとに PARCaggregate を構成できます。
構成ファイルの設定
PARCaggregate の各インスタンスは、構成ファイルを利用します。
このファイルでは、インスタンス数、日次集計計算の深夜以降の遅延、および同時ソース集計計算の最大数を指定します。
PARCrollup サービス
成績、製品実行、またはその他の可変期間の集計統計は、PARCrollup サービスによって計算およびアーカイブされます。これらの計算は、イベントが完了すると実行されるため、統計情報をすぐに利用できるようになります(PARCaggregateの定期的な実行とは対照的です)。
慰める
PARCrollup サーバーのコンソールには、ロールアップ計算用に構成されたプロセス領域のリストと、それぞれのステータスに関する指示が表示されます。
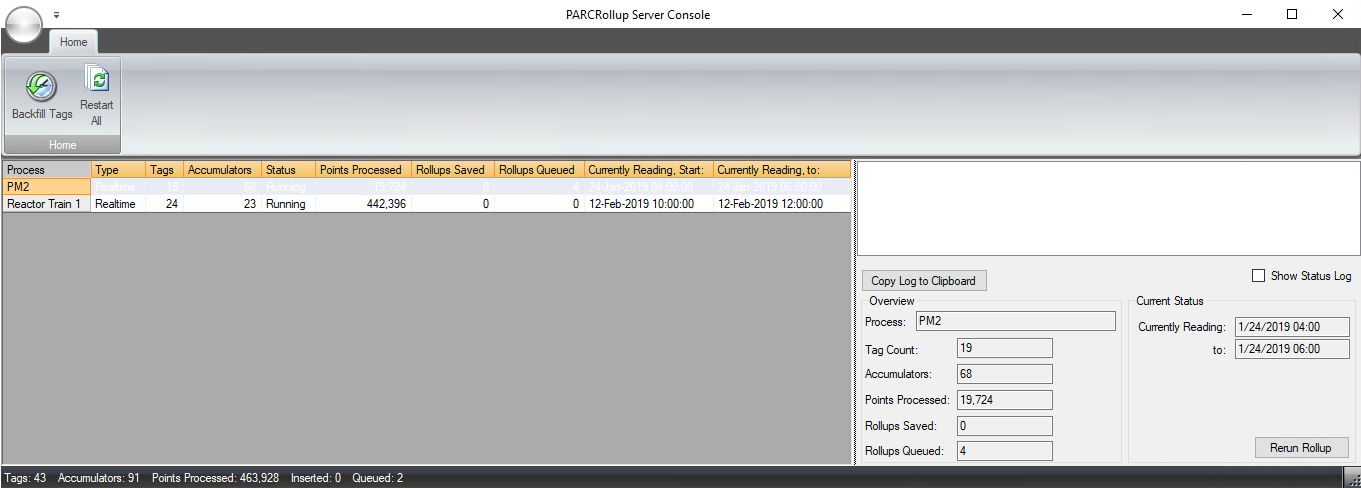
重要な注意事項
ロールアップタグスイッチは、dataPARCヒストリアン、またはPI、PHD、SQLソースなどの.NETデータシリーズを使用するその他のデータソースと連携します。
dataPARC Excel アドインには、UTag にタグ スイッチを追加するロールアップ タグを構築するためのツールが用意されています。
PARCpdeの活用
トレンド表示でPARCpdeを使用するのは非常に簡単です。プロット最適化データは、通常、トレンドに追加されるタグのデフォルトの方法として設定されます。ただし、dataPARC ツール内で PARCpde を活用する方法は他にもいくつかあります。
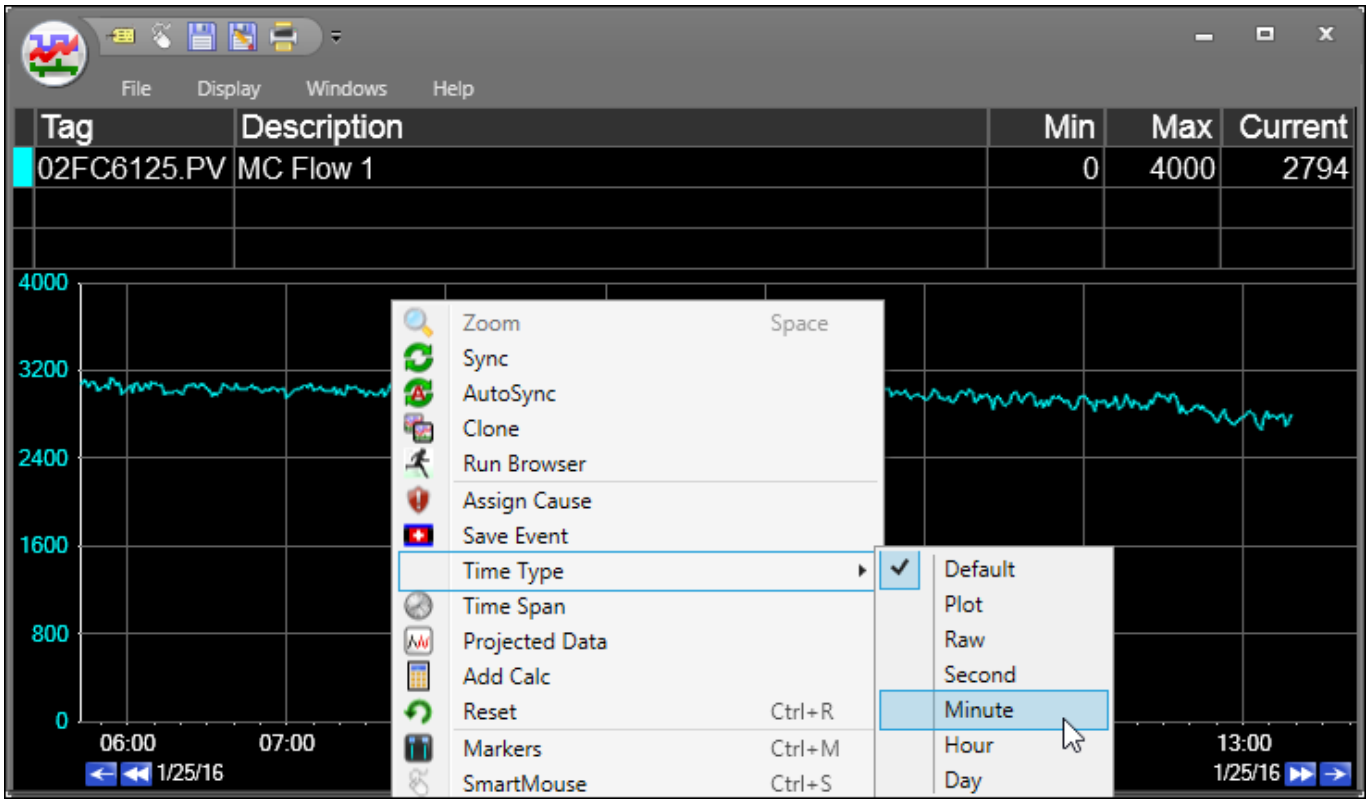
トレンド右クリックメニュー「時間タイプ」
トレンド領域を右クリックすると、以下のメニューが生成されます。
「時間タイプ」にカーソルを合わせ、目的の集計タイプを選択します。
「プロット」タイプを選択すると、プロット最適化データが利用され、PARCpdeがアクティブになることに注意してください。
「未加工」タイプを選択すると、トレンドはヒストリアンからのすべてのデータポイントを強制的にプロットし、パフォーマンスが低下する可能性があります。
タグスイッチ
タグスイッチは、トレンド表示のUTag名フィールドに直接入力できます
スラッシュ「/」の後に目的の時間タイプを使用します。時間タイプのスイッチのリスト:
/PLOT - タグのプロット削減データセットを返すようにトレンドに指示します。タグがトレンドに追加されると自動的に適用されます。
/RAW - タグの生データを返すようにトレンドに指示します。タグから /PLOT を削除するのと同じ結果になります。
/DAY - 終了時刻を含まない、午前 12:00 から午後 12:00 まで計算された時間加重平均を返します。
/HOUR - 終了時刻を含まない、時間の初め (1:00、2:00 など) から時間の終わりまで計算された時間加重平均を返します。
/MINUTE - 終了時刻を含まない、分の開始から分の終わり (5:45 から 5:46 など) まで計算された時間加重平均を返します。
/SECOND - 終了時刻を含まない、2 秒の先頭から 2 秒の終わり (5:45:07 から 5:45:08 など) まで計算された時間加重平均を返します。
/ROLLUP("Aggregate", "Period", "Grade", "RunSourceUTag") – PARCrollup アーカイブから集計データを返します。引用符で囲まれた各引数を入力する必要があります (オプションの RunSourceUTag を除く)。タグスイッチは、Excel アドインのツールを使用してタグに追加する必要があります。
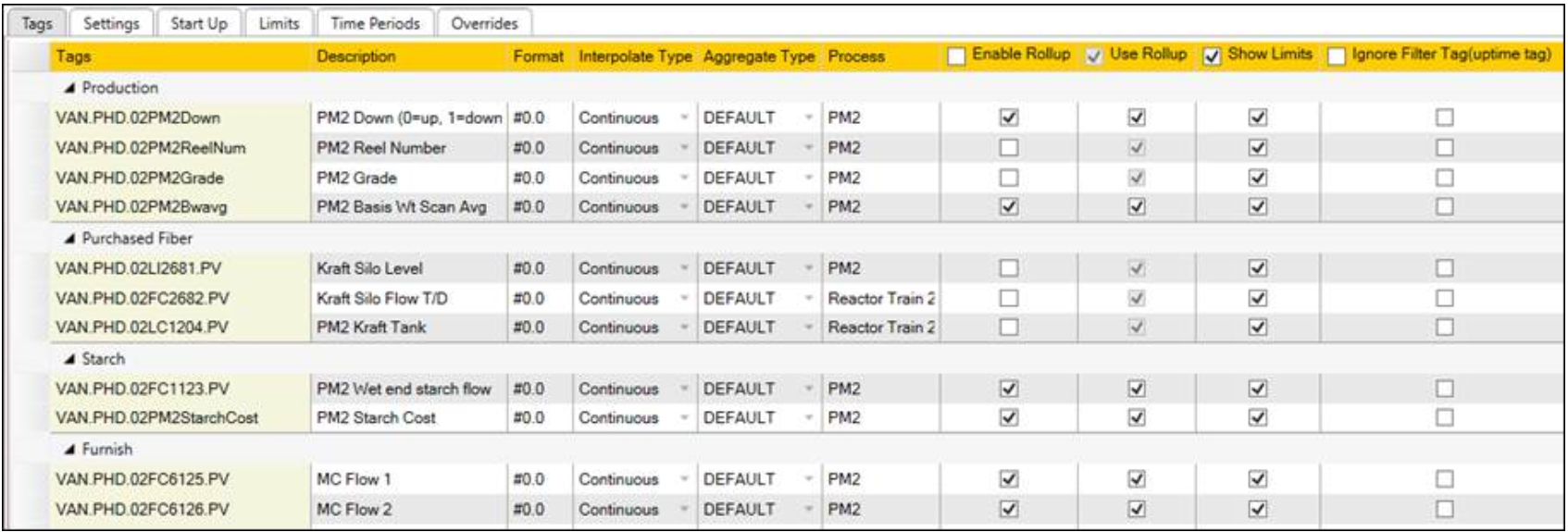
Centerline の積み上げ集計
中心線のパフォーマンスは、ロールアップ データを使用するように表示を構成することで最適化できます。[中心線コンフィギュレーション]ビューの[タグ]タブで、各タグのチェックボックスをオンにします。
Excel アドイン ロールアップ データ シート
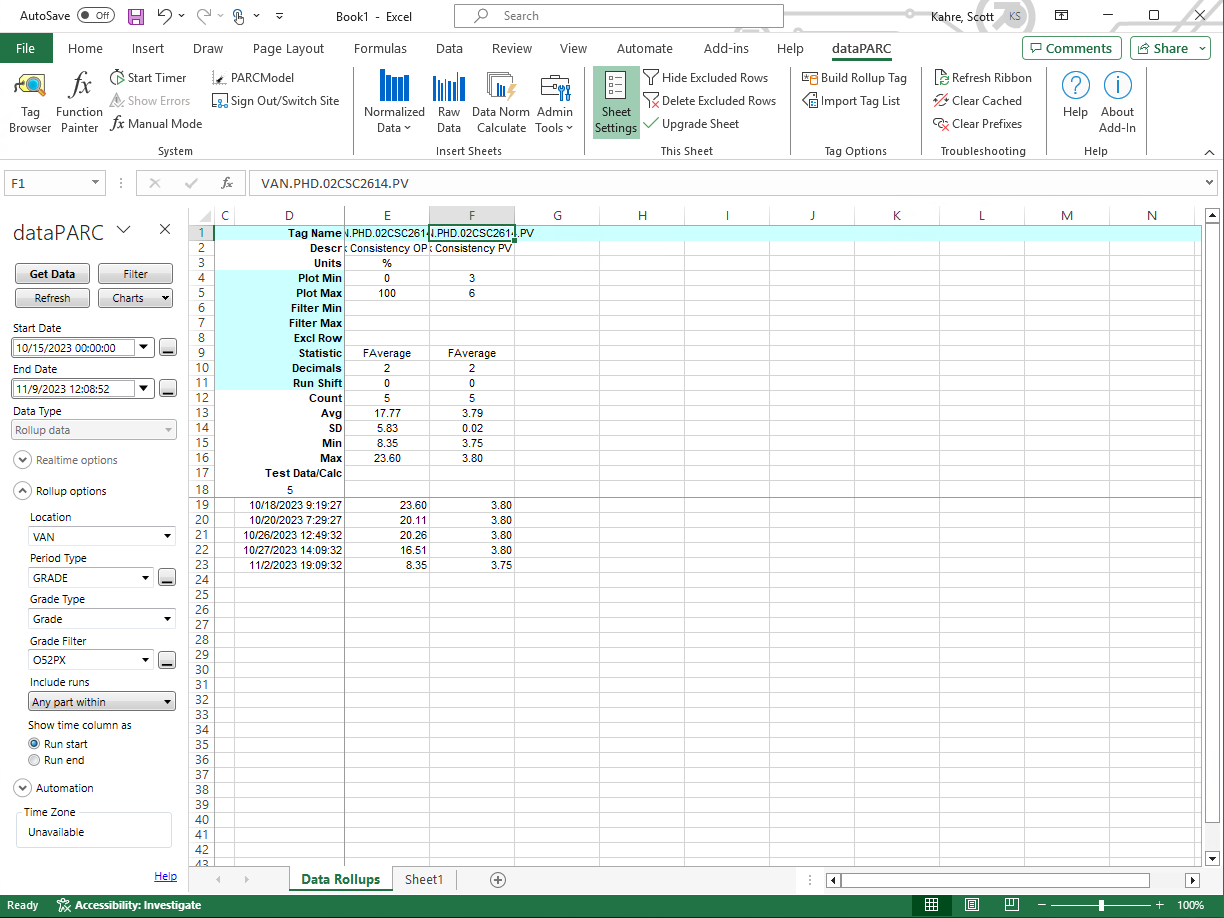
ロールアップ・データ・シートは、ロールアップ・サーバーの集計を取得するためのExcelアドインに用意されています。
構成オプションは、左側のペインで使用できます。
重要な注意事項
/PLOT と /RAW を除くすべての時間タイプでは、ソース/タグが PARCaggregate で目的の集計計算用に構成されている必要があります。集計が計算されない時間タイプを使用しようとすると、ブランクの傾向になります。
トレンドのクイック統計は、通常、現在表示されている時間タイプを使用して計算されます。したがって、クイック統計の値と生データに基づく値との間には、いくつかの小さな違いが存在する場合があります。
PARCpdeトレンド最適化アルゴリズム
PARCpdeは、最適化されたプロットのためにデータを削減するための効率的なアルゴリズムを利用しています。5 分ごとに、各タグの最初、最後、最大値、最小値が記録され、5 分の平均が生の 5 分間の平均と等しくなるように 5 番目の値が記録されます。これらの 5 つのポイントはすべて、トレンド表示に同じタイムスタンプでプロットされます。1 日以上の期間を表示すると、生データを使用してプロットされたものと視覚的に同一に見える傾向が作成されます。
次の例は、左側に生のヒストリアン データ、右側に傾向最適化データを示しています。プロットは実質的に同じですが、データポイントの数は長い期間で大きく異なることに注意してください。
.png "image(4).png")
.png "image(5).png")
.png "image(6).png")