
Methods Overview
Let's explore the methods for external applications to access data from within dataPARC. The table below shows the list of data access options along with a few key notes for each:
Access Method | Communication Protocol | Data Sources Available | Read/Write? |
OPC DA, OPC UA | Any dataPARC tag | Read only | |
SQL query | Any dataPARC tag | Read only | |
Flat file output, REST API writes, etc. | Any dataPARC tag | Read/Write | |
SDK call library | dataPARC Historian tags | Read/Write | |
HTTPS calls | dataPARC Historian tags | Read/Write | |
Rest API calls | dataPARC Historian tags | Read only |
The best access method for each situation varies based on several factors. Here is a list of questions you should ask yourself to help guide your decision:
Do I need to continuously stream real-time data? Or do I need to access historical data on-demand?
Where does the data reside? Is it in a dataPARC Historian? Or part of another data source?
What type of interface(s) does my third-party application offer?
What volume of data is needed? Is it just a few tags, or hundreds?
What data resolution is needed? Maximum read rate (1-second or less) or periodic (1-minute or more).
Do I need to write-back data to dataPARC from the third-party system?
The following sections of this article provide information about each access method relative to these questions.
dataPARC OPC Server
Two separate OPC Servers are available:
OPC UA Server for dataPARC Application Server
OPC DA or OPC UA Server for dataPARC Historian
OPC UA Server for dataPARC Application Server
Every dataPARC Application server includes at least one OPC UA Server that runs as a local service application. This service gathers data from all sources and makes it available to PARCview clients at user workstations. Third-party OPC UA client applications may also connect to this server for data connectivity.
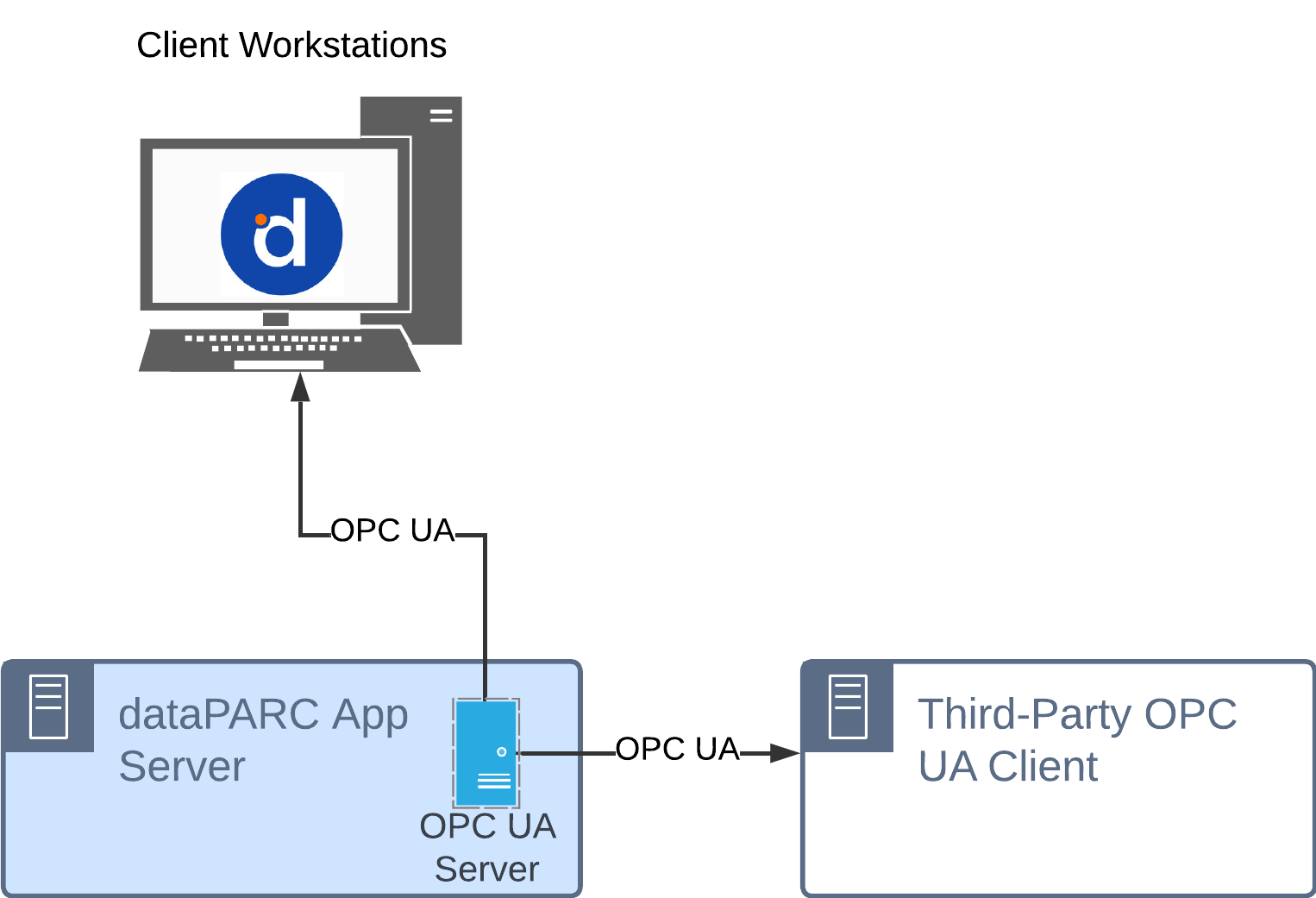
Typical Use Cases:
Streaming real-time data for large tag counts to AI or ML engines
Serving current and historical data to third-party visualization software
Providing additional process data to equipment-specific monitoring algorithms (i.e. material feed rate for a vibration monitoring device)
Points to Consider:
OPC UA is particularly suited to high-volume, continuously streaming data applications.
All data sources and types are exposed via this OPC UA Server.
Real-time data access performance is excellent; historical data access performance may suffer under heavy load.
For high-volume data needs, consider pooling multiple OPC UA Server instances or dedicating one to the third-party client. This will reduce the risk of performance degradation for PARCview clients, which also utilize the OPC UA Server for data access.
OPC DA or UA Server for dataPARC Historian
An OPC DA or UA Server can be configured to run directly on the dataPARC Historian. This offers data access to third-party OPC clients without any dataPARC Application Server involvement.
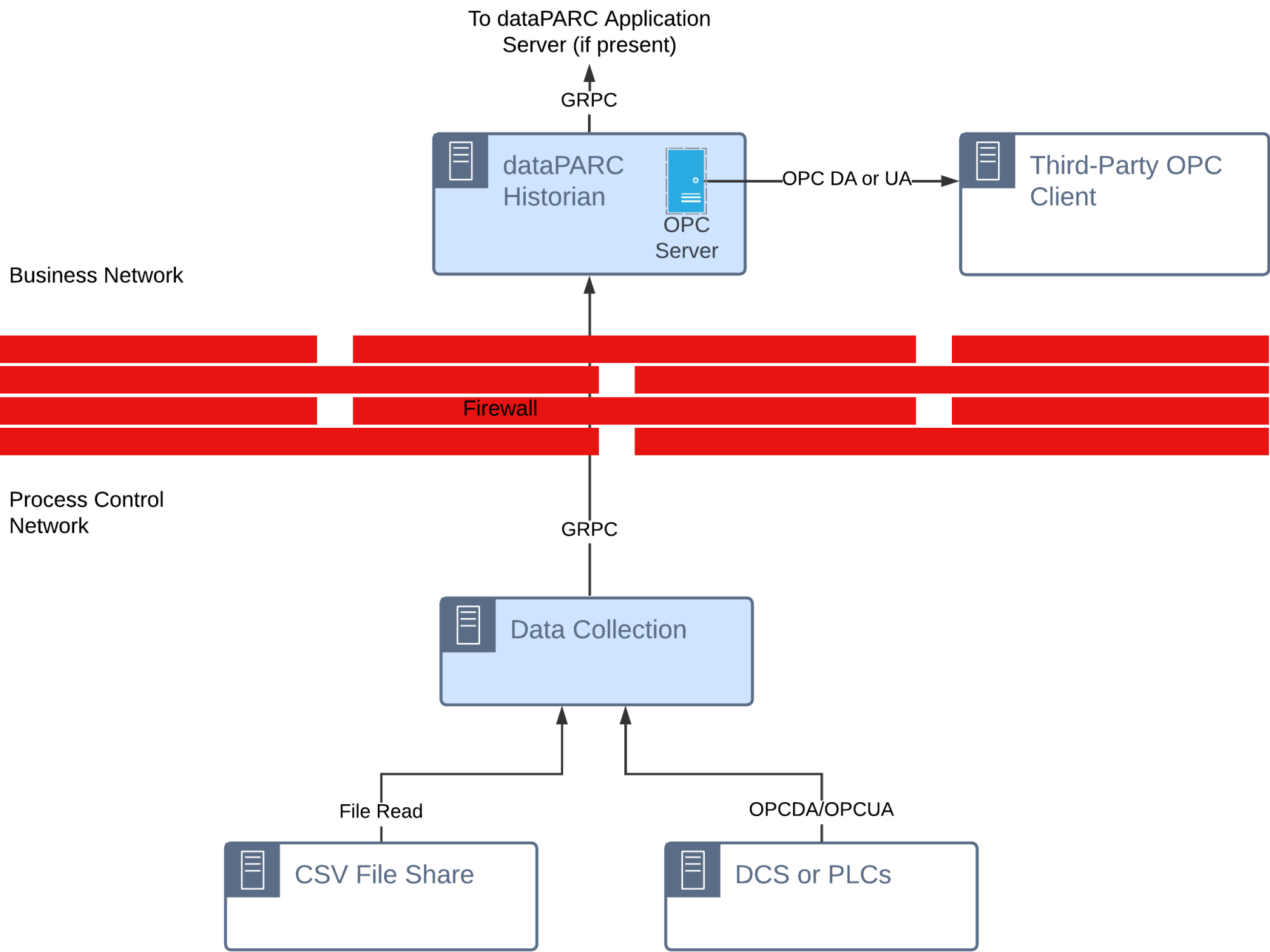
Typical Use Cases:
Streaming real-time data for large tag counts to AI or ML engines
Serving current and historical data to third-party visualization software
Providing additional process data to equipment-specific monitoring algorithms (i.e. material feed rate for a vibration monitoring device)
Points to Consider:
OPC UA is particularly suited to high-volume, continuously streaming data applications.
OPC DA is subject to DCOM hardening considerations if the OPC DA client is not running on the same Server with the dataPARC Historian.
ONLY dataPARC Historian data is exposed via this OPC UA Server. Data from other sources is not available.
Real-time data access performance is excellent; historical data access performance may suffer under heavy load.
Although no native dataPARC applications utilize this OPC Server, overall resource loading should be monitored on the Historian Server to ensure system-wide performance is maintained.
PARCdata Service
The PARCdata Service typically runs on the dataPARC Application Server and exposes data to external SQL queries. Note that the exposed data may not be part of an SQL database, but PARCdata simply acts as an agent, receiving SQL queries, fetching the requested data, and returning it to the client.
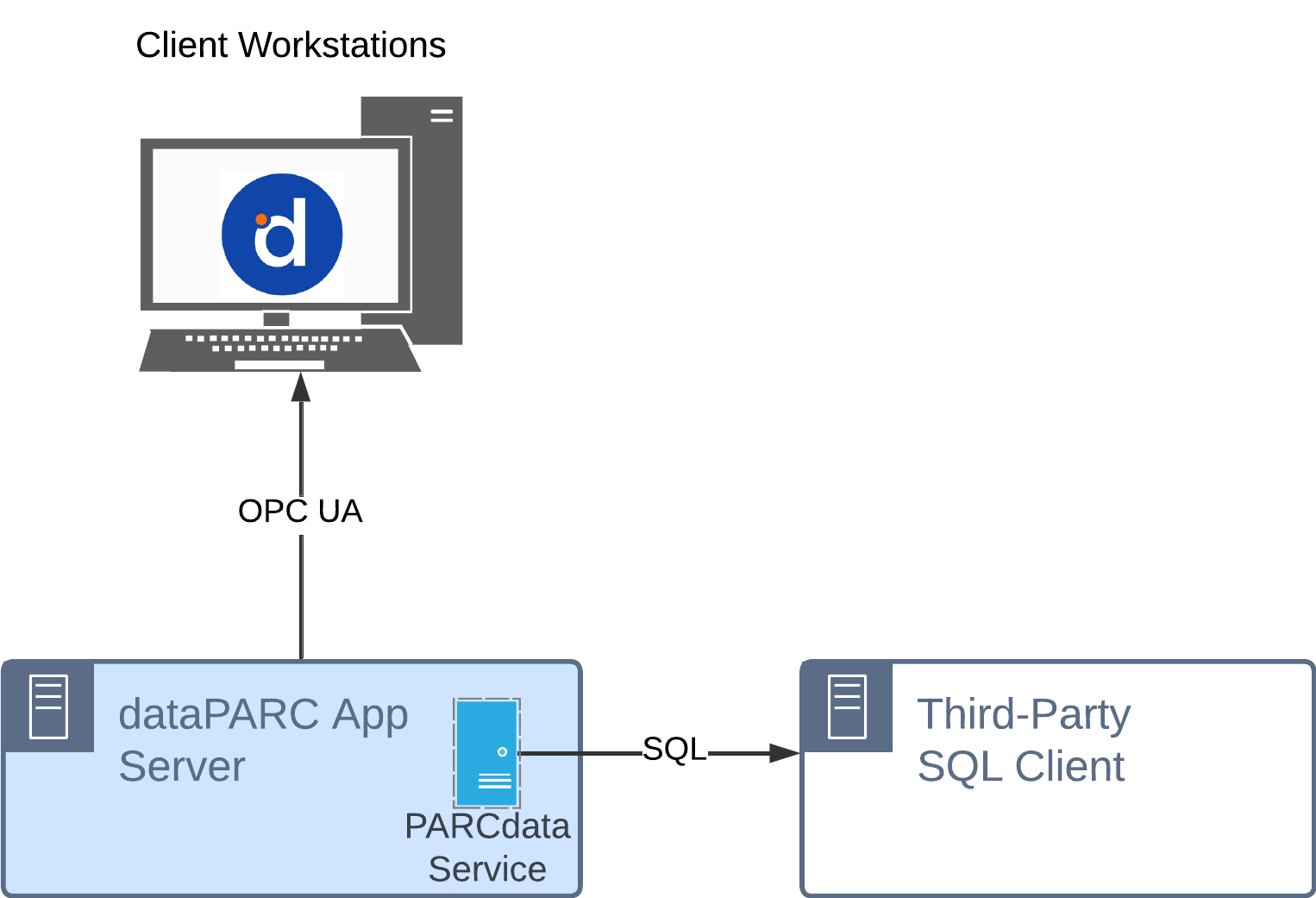
Typical Use Cases:
Supplying data to third-party reporting platforms such as PowerBI or SSRS
Serving current and historical data to third-party visualization software
Providing data to external data analysis software
Points to Consider:
The PARCdata Service (SQL) is ideal for periodic requests of low to medium volumes of data.
All data sources and types are exposed via the PARCdata Service.
dataPARC MDE data resides in SQL tables and can be accessed directly via SQL without using PARCdata.
Query structure optimization can maximize data transfer performance.
Data can be queried both in raw format, or as aggregated statistics based on time or events.
Push via PARCtask (custom)
PARCtask allows scheduled execution of custom scripts that fetch data and send it to external systems in a variety of formats. Two examples of this are building and publishing .CSV data files to a network drive or sending data to an external REST API.
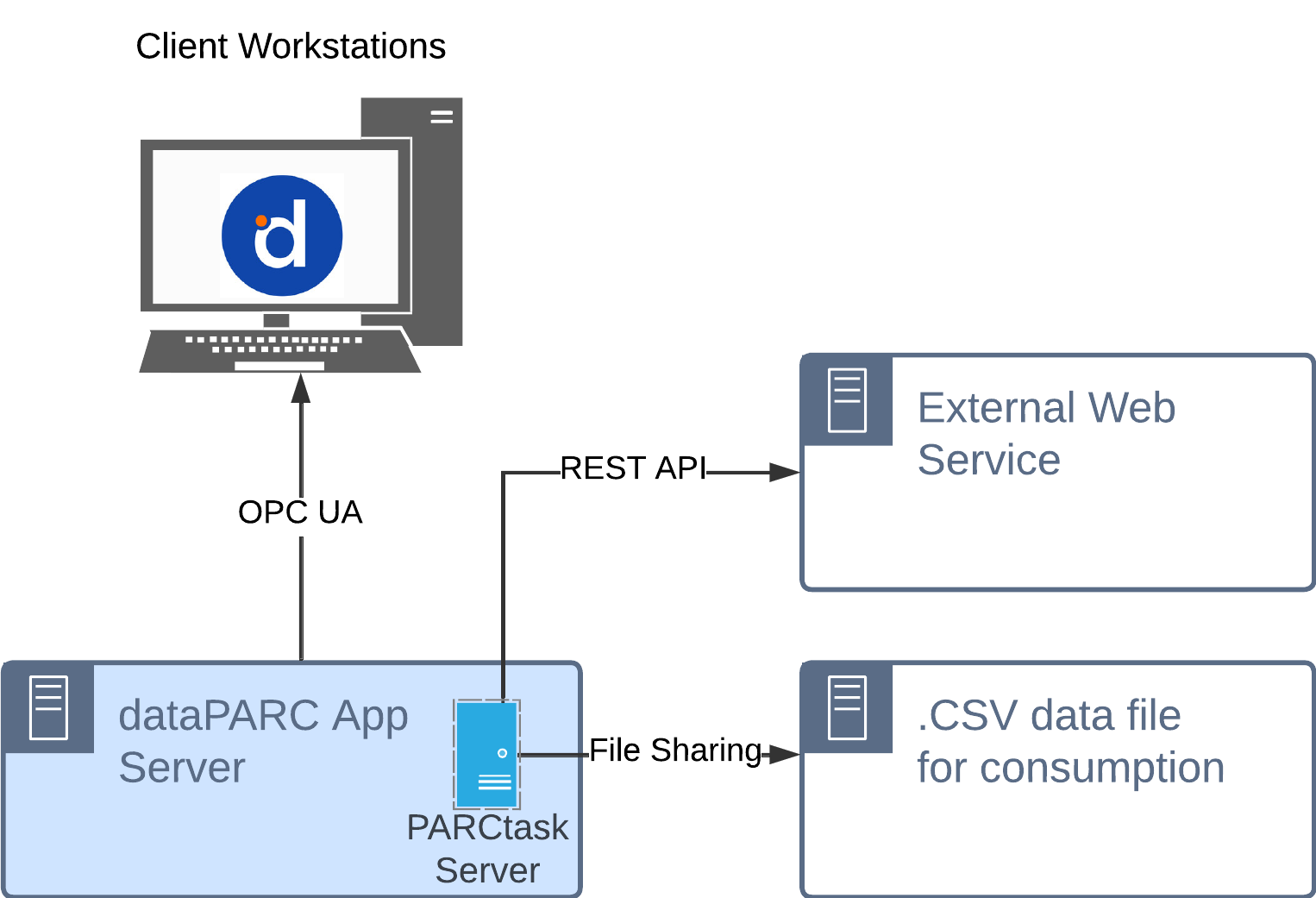
Typical Use Cases:
Supplying data to external reporting systems
Sending data to entities outside the company "walls"
Providing batches of data to external data analysis software
Points to Consider:
Data aggregation and structure are very flexible due to the vast capabilities of VB .NET scripting. However, some coding knowledge is necessary for highly custom applications of PARCtask.
PARCtask custom scripts also have the capability to read data from external files or APIs and write it to dataPARC SQL tables.
PARCtask is NOT recommended for high-frequency data transfer. Another method should be considered for transfers requiring under roughly five minute intervals.
All data sources and types can be accessed via PARCtask.
PARCtask custom scripts may require modification following major software upgrades or changes to system infrastructure.
Historian SDK
The dataPARC Historian includes a .NET SDK for programmatic data access. A library of calls provide a range of data integration functionality.
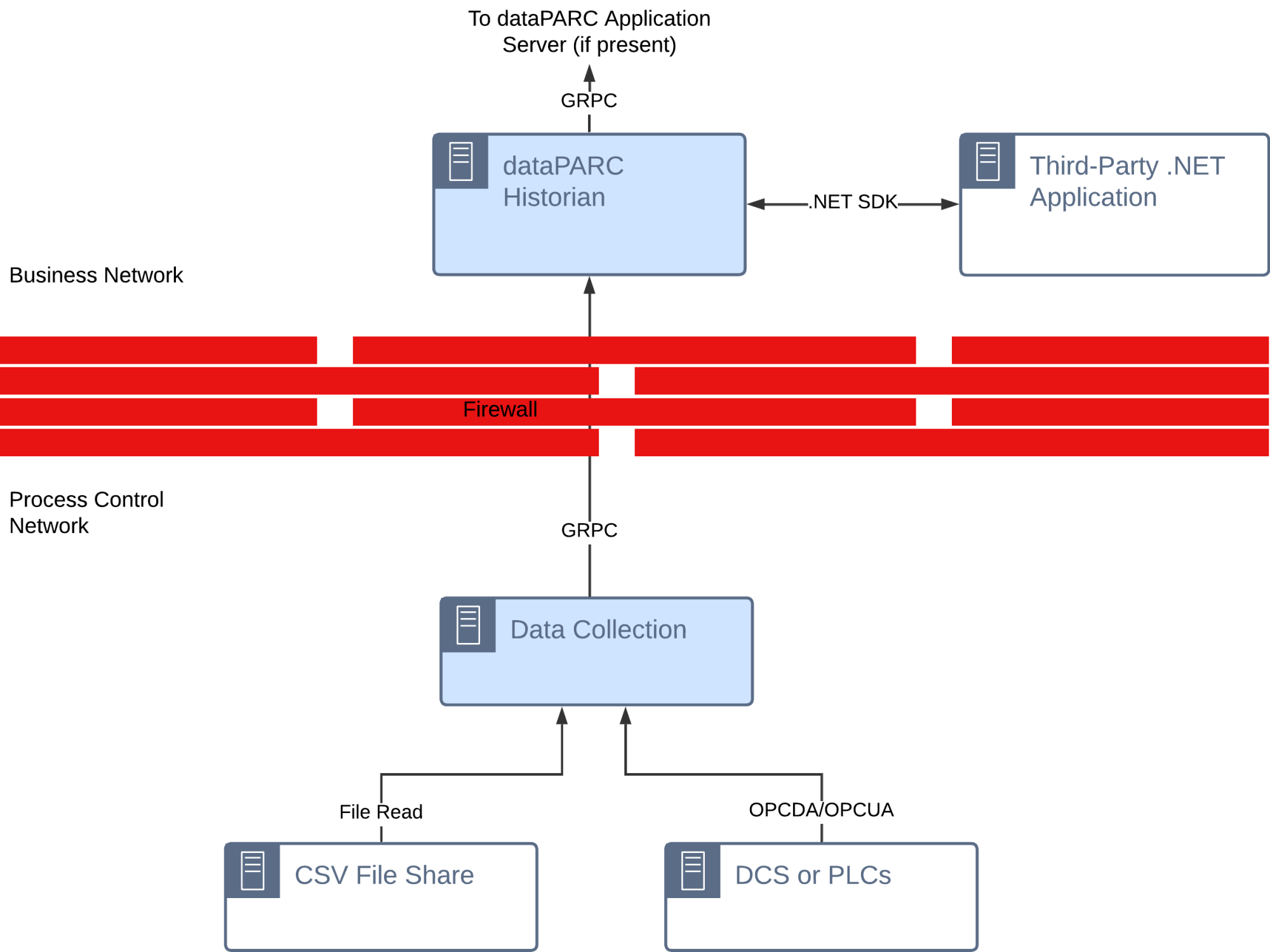
Typical Use Cases:
Streaming real-time data for large tag counts to AI or ML engines
Returning AI or ML model results to dataPARC
Serving current and historical data to third-party visualization and/or analysis software
Writing external analysis results to dataPARC
Points to Consider:
Data may be streamed or requested in "batches" or aggregates via the SDK.
Some additional components/libraries are required for implementation of the Historian SDK.
No native graphical interface is provided for the Historian SDK.
Historian SDK reference documentation is available via a GitHub Repo: https://github.com/dataPARC/store
ONLY dataPARC Historian data is exposed via this SDK. Data from other sources is not available.
The Historian SDK offers data write functionality, so external programs can publish data to the historian using this method.
Although no native dataPARC applications utilize this SDK, overall resource loading should be monitored on the Historian Server to ensure system-wide performance is maintained.
Historian gRPC
The dataPARC Historian offers gRPC endpoints for external data access.
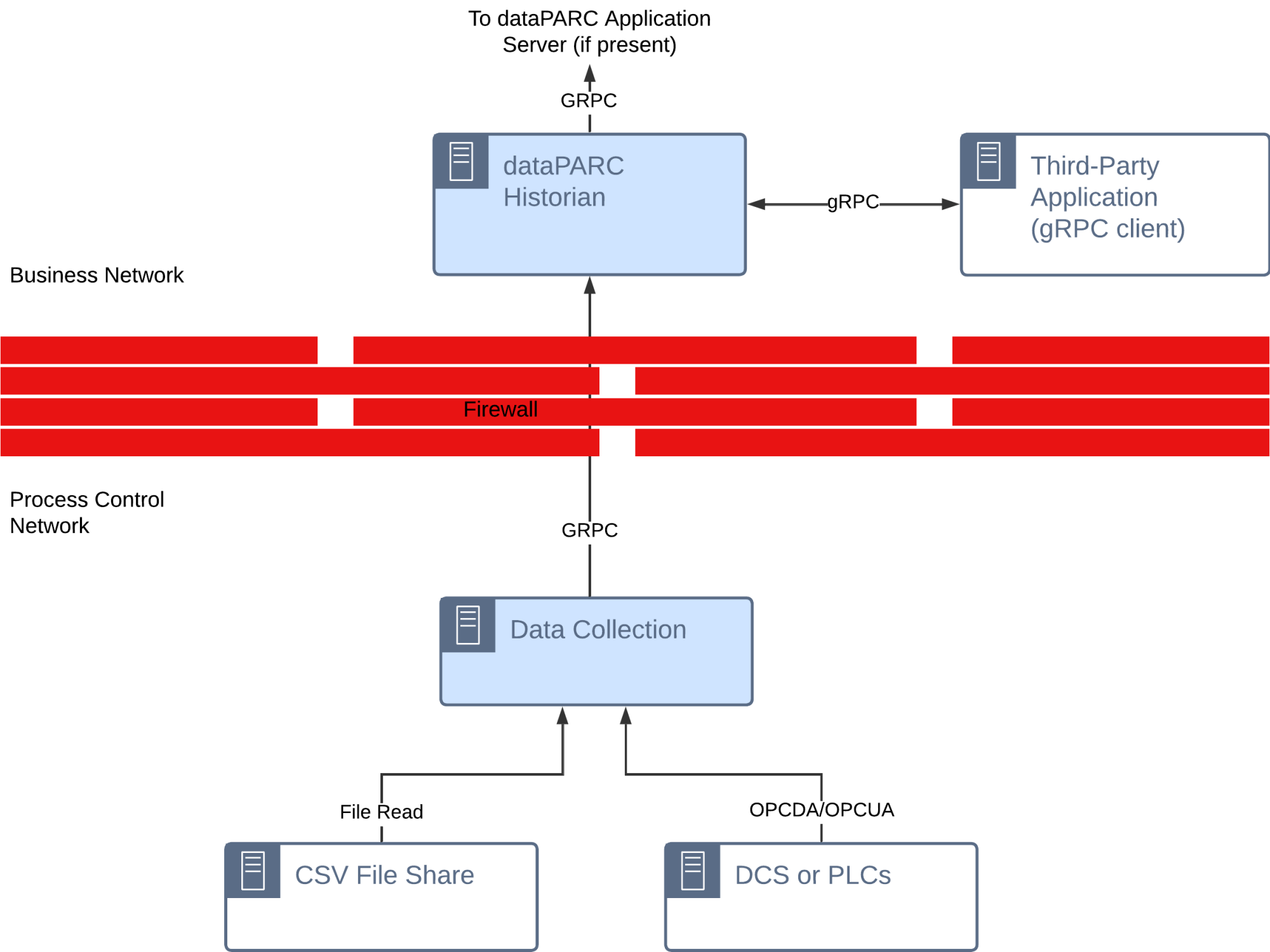
Typical Use Cases:
Streaming real-time data for large tag counts to AI or ML engines
Returning AI or ML model results to dataPARC
Serving current and historical data to third-party visualization and/or analysis software
Writing external analysis results to dataPARC
Points to Consider:
Data may be streamed or requested in "batches" or aggregates via gRPC.
Only HTTPS requests are accepted by the dataPARC Historian. This means that the gRPC client must have access to the Server's certificate.
gRPC call reference documentation is available via a GitHub Repo: https://github.com/dataPARC/store
ONLY dataPARC Historian data is exposed via gRPC. Data from other sources is not available.
dataPARC Historian gRPC calls offer data write functionality, so external programs can publish data to the historian using this method.
Overall resource loading should be monitored on the Historian Server to ensure system-wide performance is maintained.
Historian REST API
A set of REST API calls exposes dataPARC Historian data to REST clients.
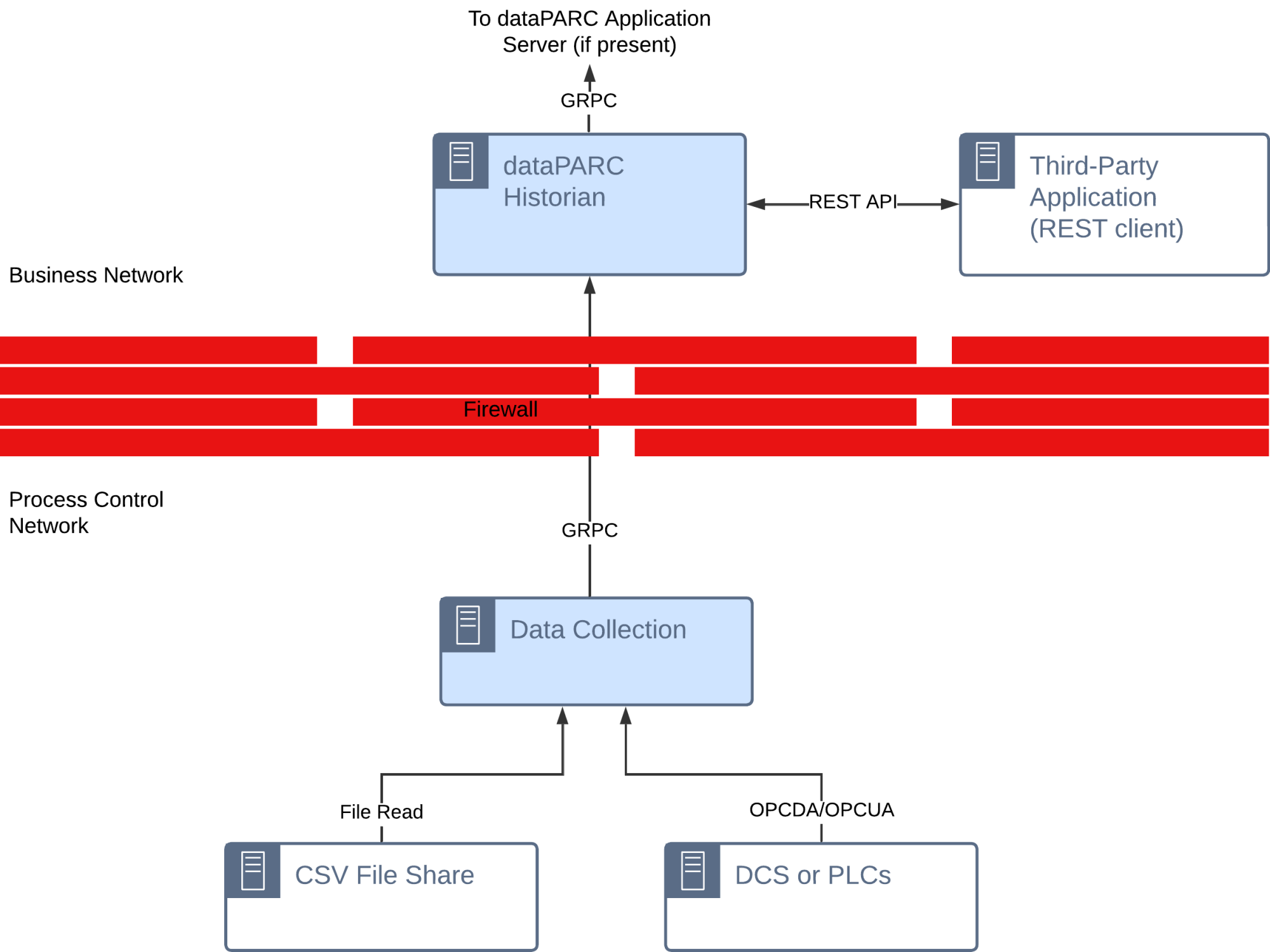
Typical Use Cases:
Supplying data to web-based third-party reporting platforms
Providing data to external data analysis software
Inserting external analysis results into dataPARC Historian tags
Points to Consider:
Only data resident in the dataPARC Historian is exposed via the Historian REST API.