
Connections to 3rd Party Data Sources
In addition to dataPARC’s native historian and internal database sources, connections can be made to a wide array of 3rd party data sources so that all integrate seamlessly into PARCview displays, reports, calculations, etc.
Summary of available connections:
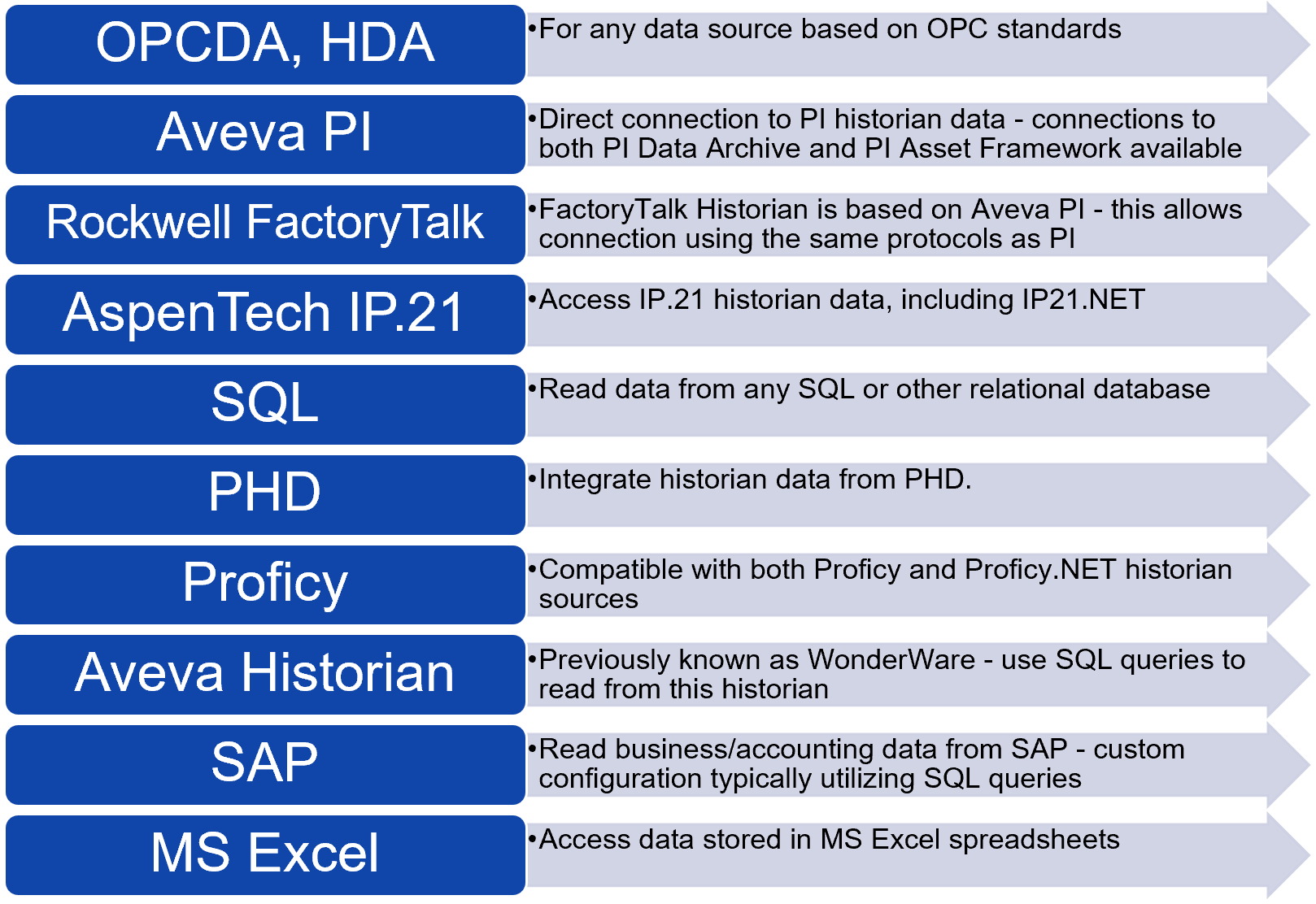
Connecting dataPARC to any combination of these sources can bring their data together in PARCview for visualization (trend, graphic, pareto, centerline, etc.). Additionally, tags from all sources can contribute to automated calculations and reports. Data from these sources are not duplicated in the dataPARC historian, thus reducing their disk space and hardware requirements.
Vendor | dataPARC Data Series | Vendor Notes |
Various | OPCDA | |
Various | OPCHDA | |
Aveva | PI | |
Aveva | PI AF | Requires AF SDK v2.5 or later |
Rockwell FactoryTalk | PI | Historian built on PI platform |
AspenTech | IP 21 | V7.3+ |
Microsoft, Oracle, various ODBC | SQL | Requires SQL Server 2008 or newer (if MS) |
Honeywell | PHD | |
GE | Proficy & Proficy.Net | Known to support Historian v. 5 - 2023 |
Aveva (WonderWare) | SQL | Requires SQL Server 2008 or newer |
SAP | SQL | |
Microsoft | Excel | Excel 365 |
OPCDA, HDA
OPC Server data sources utilizing the OPCDA or OPCHDA protocol can be configured as dataPARC data sources.
Use Cases
This connection type is best for data sources that include an OPC Server, but do not have a specific source type pre-configured in dataPARC. Each data request by a dataPARC collector app will trigger an OPC call to the source to fetch data. Aggregates can be calculated within dataPARC or read from the historian.
Common Historian ProgID List:
DeltaV Continuous Historian DeltaV.OPCHDAsvr
ABB 800XA ABB.RtdbOpcHdaServer
Rockwell FactoryTalk OSI.HDA.1
Canary CanaryLabs.OPCHDAServer
GE iFix Proficy Proficy.Historian.HDA
MOPS MOPS.MOPSOPCHDAHIST.1
Yokogawa Exaquantum Yokogawa.ExaopcHDA_PIAEEXQ.1
Dependencies | Implementation | Potential Limitations |
PARCview 5.6+ OPC Compliant Data Server | Source OPC Server must allow connections and its port must be accessible to DataPARC Server apps through any firewall. User account running DataPARC Server apps have read permissions on source OPC Server. | Data access/transfer speed may be limited depending on OPC server’s performance and network traffic. |
Aveva PI
dataPARC reads data directly from the PI historian utilizing the PI API or SDK.
Use Cases
Facilities with established PI historians can benefit from adding dataPARC for visualization, calculations, reporting, alarms and more.
Dependencies | Implementation | Potential Limitations |
dataPARC v5.6+ PI historian PI SDK (for SDK connection) | Standard feature of DataPARC Server. PI server port must be accessible to DataPARC Server apps through any firewall. PI server login credentials required. | Speed will be limited by PI server’s response times and possibly network traffic. |
Aveva PI AF
PARCview reads asset data directly from the PI historian if clients also have the PI AF SDK installed, OR utilizes a Remote UA server if the dataPARC server has the PI AF SDK installed (clients are routed through the server). Exposes asset element and template hierarchy and allows selecting entire tag templates for visualization. Event frames are not exposed via this connection.
Use Cases
Facilities with established PI historians with Asset Framework can connect dataPARC using the PI AF SDK. This allows access to the Asset Framework and can also improve long-term data query performance.
Dependencies | Implementation | Potential Limitations |
PARCview version 7.0.1.5+ PI historian v3.2 SR1+ PI AF SDK v2.5+ | Standard feature of DataPARC Server. PI server port must be accessible to DataPARC Server apps through any firewall. PI server login credentials required. | Speed will be limited by PI server’s response times and possibly network traffic. |
Rockwell FactoryTalk
The Rockwell FactoryTalk historian is based on the Aveva PI historian, so all connection options/settings are similar.
Use Cases
Facilities with Rockwell FactoryTalk historians can benefit from adding dataPARC for visualization, calculations, reporting, alarms and more.
Dependencies | Implementation | Potential Limitations |
PARCview version 7.0.1.5+ See PI dependencies above | Standard feature of DataPARC Server. FactoryTalk server port must be accessible to DataPARC Server apps through any firewall. FactoryTalk server login credentials required. | Speed will be limited by FactoryTalk server’s response times and possibly network traffic. |
Aspentech IP.21
dataPARC reads data directly from the IP.21 historian utilizing the Process Explorer API for data reads and the IPSQL ODBC connection type for reading the tag list.
Use Cases
Facilities with established IP.21 historians can benefit from adding dataPARC for visualization, calculations, reporting, alarms and more.
Dependencies | Implementation | Potential Limitations |
dataPARC v5.6+ Aspen Process Data Aspen Process Explorer Aspen SQLplus aspenONE Diagnostics Aspen ODBC Drivers | Standard feature of DataPARC Server. IP.21 server port must be accessible to DataPARC Server apps through any firewall. SQL tag list required. ODBC Driver must be 32-bit for dataPARC 5.6, must match architecture for dataPARC 7.x. IP.21.NET source type in recent dataPARC versions is faster and allows text tags. User (vs. Public) data sources require correct user account running DataPARC Server services. | Speed will be limited by IP.21 server’s response times and possibly network traffic. |
SQL
dataPARC reads data from an SQL database using standard SQL calls.
Use Cases
Facilities with pre-existing and/or custom data histories in SQL databases can add these as a dataPARC source for full functionality in visualization, calculations, reporting, alarms and more.
Common Databases | Vendor | Notes |
MS SQL Server Oracle PostgreSQL MySQL SAP ECC SAP Hana Snowflake Databricks Lakehouse MS Access Plant Applications QIS DELMIAWorks Elixir Ecto MillTools Optivision STARLIMS | Microsoft Oracle PostgreSQL Dev. Group Oracle SAP SAP Snowflake Databricks Microsoft GE QiSoft Solidworks Elixir School Panther Honeywell STARLIMS | Cloud-only Cloud-only Cloud-only Uses Oracle Database wrapper a.k.a. Honeywell Production Management |
Common Queries
Tag Scripts
Tag List – Returns list of tags used by the template
Tag Info. – Returns tag information
Limit – Returns tag limits
Read Data Scripts
Current – Returns current value
Data – Returns raw data for specified time period
Data Prior – Returns value just prior to start time for use as start bound point
Data After – Returns value just after end time for use as end bound point
Projection – Returns projected (future) data
Data Plot – Returns plot-reduced data set for trends
Data Aggregate – Returns aggregated data
Data Providers
.NET Framework data provider | Description |
.NET Framework Data Provider for SQL Server | Provides data access for Microsoft SQL Server. Uses the System.Data.SqlClient namespace. |
.NET Framework Data Provider for OLE DB | For data sources exposed by using OLE DB. Uses the System.Data.OleDb namespace. |
.NET Framework Data Provider for ODBC | For data sources exposed by using ODBC. Uses the System.Data.Odbc namespace. |
.NET Framework Data Provider for Oracle | For Oracle data sources. The .NET Framework Data Provider for Oracle supports Oracle client software version 8.1.7 and later, and uses the System.Data.OracleClient namespace. |
**Note: dataPARC’s SQL dataseries does not support EntityClient Provider (System.Data.EntityClient) or .NET Framework Data Provider for SQL Server Compact 4.0 (System.Data.SqlServerCe).
PHD
dataPARC reads data directly from the PHD historian utilizing the Com, ComRemote, NetRemote, NetApi200 or NetApi150 connection type.
Use Cases
Facilities with established PHD historians can benefit from adding dataPARC for visualization, calculations, reporting, alarms and more. Aggregates can be calculated within dataPARC or read from historian.
Dependencies | Implementation | Potential Limitations |
dataPARC v5.6+ PHD historian PHD API (distributed with Uniformance) | Standard feature of DataPARC Server. PHD server port must be accessible to DataPARC Server apps through any firewall. PHD API .dll files must be installed and accessible to DataPARC Server apps. SQL tag list template required. | Speed will be limited by the PHD server’s response times and possibly network traffic. |
Proficy
PARCview reads data directly from the Proficy historian if clients also have the Proficy client installed, otherwise they are routed through the dataPARC server using the HDA remoting source. Can use API to read from legacy Historian (v5 and v6) or SDK for newer versions of Proficy Historian.
Use Cases
Facilities with established Proficy historians can benefit from adding dataPARC for visualization, calculations, reporting, alarms and more. Aggregates can be calculated within dataPARC or read from the historian.
Dependencies | Implementation | Potential Limitations |
dataPARC v5.6+ Proficy Historian User API v6.x+ Proficy Historian Client Access Assembly Proficy Client Tools | Standard feature of DataPARC Server. Proficy server port must be accessible to DataPARC Server apps through any firewall. Proficy SDK/client tools must be installed on dataPARC server. Older dataPARC versions need Proficy.Historian.ClientAccess.API.dll copied to root of PARCview folder. Proficy username/password required. | Speed will be limited by the Proficy server’s response times and possibly network traffic. SDK is preferred. |
Aveva Historian (previously WonderWare)
Aveva Historian (WonderWare) data can be read by a special setup of the dataPARC SQL source type.
Use Cases
Facilities with established Aveva historians (WonderWare) can benefit from adding dataPARC for visualization, calculations, reporting, alarms and more.
Dependencies | Implementation | Potential Limitations |
dataPARC v5.6+ MS SQL server 2008+ | Standard feature of DataPARC Server. SQL Server must be installed and accessible to DataPARC Server apps through any firewall. SQL username/password required. SQL tag template required. | Speed will be limited by the SQL server’s response times and possibly network traffic. |
SAP (custom configuration)
Business and/or accounting data can be read from SAP, typically via SQL queries. Requires some customization for each application.
Use Cases
SAP systems can provide material inventory or usage, cost, production or other data to dataPARC to enable inclusion in visualization, reporting, etc. alongside process and lab data.
Dependencies | Implementation | Potential Limitations |
dataPARC v5.6+ Database server or web server to expose SAP | SAP database must be exposed by customer, then dataPARC engineers will write a client to read/write SAP data. | Speed will be limited by the data server’s response times and possibly network traffic. Client may need updates if changes are made to SAP database. |
Excel
dataPARC reads timeseries data stored in an MS Excel spreadsheet. Data is read on an ad-hoc basis, updating only when the tag’s dataPARC display is initially loaded or modified.
Use Cases
Facilities with archived historical data, Lab or other manual-entry data stored in Excel spreadsheets can connect to these spreadsheets via the Tag Browser. This method is not intended for large quantities of data or long histories due to Excel file size and load speed limitations.
Dependencies | Implementation | Potential Limitations |
dataPARC v5.6+ Microsoft Excel v2010+ | Standard feature of dataPARC client apps Tag Browser. Excel data file must be saved in location accessible to dataPARC client and not be “locked” (i.e. Office sharing controls must release it). Excel sheet headers and data structure must remain as originally specified in tag browser. | Spreadsheet files must be loaded each time a newly opened client display accesses data. File size and location (local vs. network) will impact speed. |